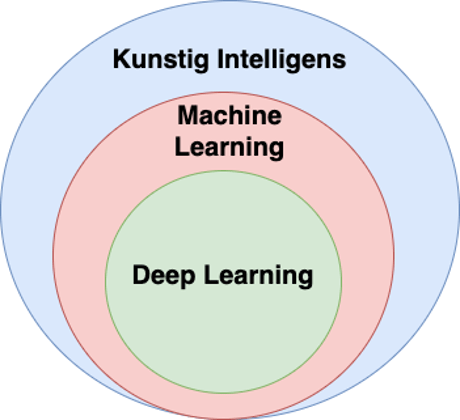
Hvad er forskellen på kunstig intelligens, machine learning og deep learning
Overordnet kan man sige, at det grundlæggende princip for al kunstig intelligens er systematisk at søge efter en løsning. Jo mere man ved, jo mindre skal man søge efter et svar, og omvendt – jo mere man søger, jo mindre viden har man brug for på forhånd. Bag dette relativt simple princip, er der gennem årene er blevet udviklet mange forskellige teknikker inden for kunstig intelligens.
Klassiske teknikker inden for kunstig intelligens er metoder og algoritmer, der blev udviklet før den seneste bølge af maskinlæring og dyb læring. Disse teknikker fokuserer ofte på at efterligne menneskelig beslutningstagning med formelle, veldefinerede regler og logikker.
Et eksempel er søgealgoritmer, der udgør grundstenen i mange AI-systemer. Den simpleste søge-algoritme gennemgår hvert element i en liste af muligheder fra start til slut for at finde en bestemt værdi eller løsning. Den er meget simpel, men ineffektiv for store datamængder, da den kræver, at man ser på hvert eneste element, indtil det ønskede findes eller listen er fuldt gennemgået. Der er derfor gennem årene opfundet et hav smartere måder at søge på, hvor man strukturerer data på forskellige måder (f.eks. ved at sortere dem ud fra forskellige principper), hvilket kan øge effektiviteten.
Symbolbaseret AI, fokuserer på anvendelsen af logik og symbolske repræsentationer til at simulere menneskelig tankegang. Denne tilgang anvendes i expert-systemer, som efterligner menneskelig ekspertise inden for specifikke domæner. Ved at bruge et regelsæt kan disse systemer udlede nye oplysninger og træffe beslutninger baseret på eksisterende viden.
Regelbaserede systemer fungerer gennem et sæt af definerede regler, der styrer systemets handlinger. Typisk struktureres disse systemer omkring IF-THEN regler, der udløser bestemte handlinger, når foruddefinerede betingelser er opfyldt. Denne metode er særdeles i situationer, hvor beslutninger skal træffes klart og konsekvent, og hvor parametrene for disse beslutninger er velkendte og forudsigelige.
Beslutningstræer er effektive værktøjer til beslutningstagning og klassificering, der repræsenterer beslutninger og deres mulige konsekvenser i en træstruktur. Hver gren i træet symboliserer et valg mellem alternative handlinger, mens bladene repræsenterer mulige udfald. Beslutningstræer er særligt værdifulde i beslutningsanalyse, da de hjælper med at visualisere og evaluere de forskellige strategier for at opnå det bedst mulige resultat.
Maskinlæring er en underkategori af kunstig intelligens, der fokuserer på at udvikle algoritmer og statistiske modeller, som computer-systemer kan bruge til at udføre specifikke opgaver uden at være eksplicit programmeret til det. I stedet lærer disse systemer og forbedrer deres præstation baseret på erfaring (dvs. data). Grundlaget for maskinlæring er at give maskiner evnen til at lære fra og tolke data, så de kan træffe beslutninger.
Dyb Læring (Deep Learning) er en mere avanceret delmængde af maskinlæring. Den bruger komplekse neurale netværk med mange lag (deraf navnet “dyb”), til at simulerer den menneskelige hjernes struktur og funktion. Dyb læring er særligt effektiv til opgaver som billed- og talegenkendelse, hvor den kan identificere mønstre og karakteristika.
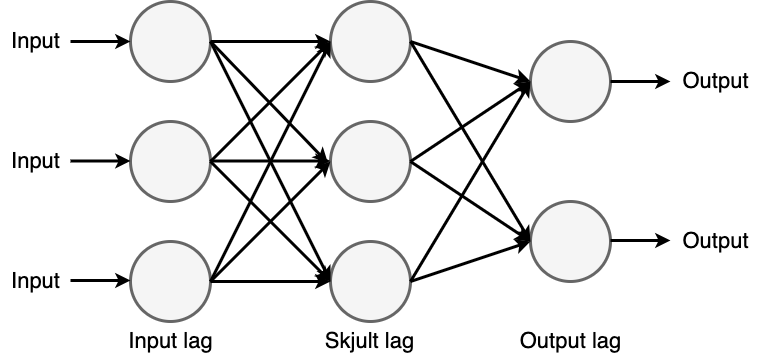
Neurale netværk. Dybest set er hjernen bygget op af mange sammenkoblede neuroner i et kompliceret netværk af nervebaner. Neuronerne i hjernen er også bindeleddet mellem sanserne (input) og vores muskler (output). Når et bestemt sanseinput rammer de relevante neuroner, vil de sende nerveimpulser videre til en række forbundne neuroner. Endelig kan disse nerveimpulser sende beskeder til musklerne, som i sidste ende kan kontrollere den kropslige reaktion. Dette system er fælles for stort set alle levende organismer bortset fra de meget simple, som f.eks. bakterier.
Den konkrete forbindelse mellem input (sanser) og output (handling) er resultatet af samspillet mellem arv og miljø. Visse ting gør vi instinktivt, som f.eks. at trække vejret. I andre tilfælde er vi trænet til at reagere på en bestemt måde i en bestemt situation. Det sker i løbet af vores opvækst gennem vores erfaringer og generelle opdragelse. Hvis man ser på, hvordan neurale netværk bruges i en computer, bestemmes det specifikke reaktionsmønster i et neuralt netværk ved at indstille en række vægte (dvs. en række numeriske værdier), der bestemmer, hvornår et enkelt neuron skal sende et signal videre til de tilsluttede neuroner. At få et neuralt netværk til at outputte på en bestemt måde i en bestemt situation indebærer derfor at finde en række tal, der får netværket til at opføre sig som ønsket. Det lyder måske simpelt, men det er svært, da antallet af vægte og forbindelser ofte er ekstremt stort.
Derfor finder man disse vægte indirekte: Man træner sit neurale netværk ved at lade det øve sig på en stor mængde input, hvor man kender det rigtige svar. Ved at korrigere vægtene via forskellige matematiske formler baseret på forskellen mellem dets eget resultat og det rigtige resultat, kommer netværket gradvist tættere og tættere på at kunne reagere korrekt på træningsinputtet – for til sidst at kunne reagere korrekt på input, som det aldrig er blevet præsenteret for før.
Den grunlæggende princip bag deep learning er at træne en stor mængde kunstige neurale netværk ved hjælp af computere. Deep learning-algoritmer kan lære komplekse og abstrakte repræsentationer af data. De kan trænes på store datasæt for at opnå høje niveauer af nøjagtighed i opgaver som billedgenkendelse, naturlig sprogbehandling og beslutningstagning.
I deep learning består neurale netværk typisk af flere lag af indbyrdes forbundne noder, hvor hvert lag lærer stadig mere komplekse repræsentationer af dataene. Netværkets parametre justeres under træningen ved hjælp af en proces, der kaldes backpropagation, som gør det muligt for netværket at lære af sine fejl og gradvist forbedre sin præstation.
Deep learning er blevet et af de vigtigste og hurtigst voksende områder inden for maskinlæring. Det ligger bag mange af de seneste gennembrud inden for kunstig intelligens, herunder betydelige forbedringer inden for computersyn, talegenkendelse og naturlig sprogbehandling.
Evolutionær programmering og kunstigt liv er et andet eksempel på, hvordan datalogien låner et koncept fra naturen. I dette tilfælde er den genetiske udvælgelsesproces princippet om, at den bedst egnede overlever. Det grundlæggende princip består i at generere en population af tilfældige løsninger, for eksempel i form af små kodestykker. Derefter vurderer man, hvilke af de genererede løsninger der fungerer bedst i forhold til det givne problem, og vælger så nogle få af de bedste. Ved at lade de valgte løsninger “parre sig”, dvs. blande kodesegmenter, skabes en ny population af løsninger. For at forny det genetiske materiale udfører man ofte det, man i biologien kalder en mutation. Det betyder, at man tilføjer nogle tilfældige ændringer. Den nye population er derfor baseret på de bedst udvalgte fra den tidligere population, inklusive flere mutationer. Løsninger kan udvikles trin for trin, så processen kan fortsætte. Processen stopper, når kvaliteten af de bedste løsninger ikke længere forbedres, eller når processen har kørt et bestemt antal generationer. Således vil den bedste løsning i den sidste generation være den, der for eksempel danner robottens hjerne.
I kunstigt liv, ofte forkortet til Alife, forsøger at forstå og genskabe livets egenskaber gennem lignende evolutions- og økosystemsimulationer. Disse simuleringer bruger algoritmer, der efterligner naturlig selektion og genetisk variation, hvilket tillader forskere at observere, hvordan organismer og adfærd kan udvikle sig over tid under forskellige betingelser. Et eksempel er Karl Sims’ arbejde i 1990’erne, hvor han udviklede virtuelle skabninger, der kunne udvikle sig til at løse specifikke fysiske opgaver i en simuleret tredimensionel verden.
Et andet vigtigt forskningsområde inden for kunstigt liv er studiet af selvorganiserede systemer. Dette område udforsker, hvordan kompleks adfærd kan opstå fra enkle interaktioner mellem enkeltelementer. Gennem regler (for eksempel Conways spil ‘Livet’), observerer forskere, hvordan orden og struktur spontant kan opstå fra tilsyneladende tilfældige eller simple udgangspunkter. Ud over de teoretiske aspekter har kunstigt liv praktiske anvendelser. I robotik kan principperne fra kunstigt liv anvendes til at designe robotter, der bedre kan tilpasse sig uforudsete ændringer i deres miljø gennem evolutionslignende processer. I økologiske simuleringer kan forskere bruge kunstigt liv til at forudsige, hvordan ændringer i miljøet kan påvirke forskellige arter og hele økosystemer, hvilket giver værdifuld indsigt i bevaringsbestræbelser.
Reinforcement Learning er en måde at lære, hvordan man maksimerer en belønning. Den lærende får ikke at vide, hvilke handlinger der skal udføres (hvilket ellers er almindeligt i de fleste andre læringsmekanismer). I stedet lærer man, hvilke handlinger der belønnes mest, ved at prøve dem. I de mest interessante og krævende tilfælde kan handlinger påvirke den umiddelbare belønning, den næste situation og alle efterfølgende belønninger. Reinforcement learning adskiller sig fra f.eks. neurale netværk ved ikke at skulle trænes eller trænes med de rigtige svar først. Fordelen ved dette er, at man ikke på forhånd behøver at have eksempler på de situationer, som læringsalgoritmen skal håndtere – man definerer et problem. Så finder algoritmen selv svaret. Reinforcement learning er inspireret af tidlig forskning i adfærdspsykologi, bl.a. udført af den russiske psykolog Ivan Pavlov, som lavede forsøg med hunde i begyndelsen af 1900-tallet. Han kunne fremkalde forskellige ønskede adfærdsreflekser hos hundene ved at belønne den ønskede respons på en given stimulus (påvirkning). For eksempel kunne han få deres mundvand til at løbe, når de hørte en klokke, fordi han de første mange gange, han ringede med klokken, gav dem en godbid bagefter. Da han holdt op med at give dem godbidden, fortsatte mundvandsrefleksen. Han kaldte princippet for en positiv betingelse.
Selvom udviklingen inden for kunstig intelligens har været i gang i mange år, har den primært været forbeholdt forskningsmiljøer og nogle få store virksomheder som IBM. I de senere år er virksomheder som Google, Facebook, Amazon og andre også begyndt at skyde mange penge i området. Google har investeret i en række virksomheder inden for kunstig intelligens i løbet af de seneste år.
For eksempel annoncerede Google i januar 2014, at de havde opkøbt den lille iværksættervirksomhed DeepMind Technologies, som har udviklet et system baseret på neurale netværk, der blandt andet kan lære sig selv at spille simple computerspil som Breakout, Pong og Space Invaders. Købsprisen blev ikke offentliggjort, men anslås til at være mindst 400 millioner dollars. Et utroligt beløb, for på det tidspunkt havde virksomheden kun eksisteret i et par år og bestod af 3-4 mand. En betingelse for købet var, at Google nedsatte et udvalg, der skulle se på de etiske konsekvenser af kunstig intelligens.
På samme måde som IBM skabte overskrifter, da de slog skakmesteren Kasparov i 1997, skabte Deep Mind overskrifter næsten 20 år senere, da deres AlphaGo-program slog en menneskelig professionel Go-spiller, verdensmesteren Lee Sedol, i en kamp på fem partier i 2016.